Congress.wiki
Simplifying Congressional Information for Everyone
September 1, 2021 - October 20, 2024
Updated October 28, 2024
https://congress.wikiDoes Congress represent you? In 2021, I found myself frustrated by the complexity of learning about Congress and our representatives. This led me to create Congress.wiki, a user-friendly platform designed to guide citizens through the intricacies of the U.S. Congress.
Congress.wiki Landing Page
The Challenge
Existing congressional resources overwhelm users with dense documentation and complex interfaces. Sites like Congress.gov require extensive help centers with 50+ pages of instructions, creating significant barriers for citizens trying to engage with their government.
My Approach
Congress.wiki aims to make congressional information intuitive and engaging through thoughtful design principles:
- Show, Don't Tell: Design interfaces that are self-explanatory without lengthy documentation.
- Visual Recognition: Use photos and icons instead of text-heavy navigation, helping users quickly identify representatives and build lasting recognition.
- Geographic Context: Present congressional data in relation to constituents' locations, strengthening the connection between citizens and their representatives.
- Focused Information: Display only the most relevant data upfront, with additional context available through progressive disclosure.
- Respectful Presentation: Honor the importance of congressional data while making it approachable.
- Meaningful Engagement: Reserve calls-to-action for appropriate moments to maintain user trust.
Comprehensive Data Collection
One of the most critical challenges in building Congress.wiki was data collection. While congressional data is publicly available, it's fragmented across numerous sources and requires significant effort to aggregate comprehensively.
Challenges
- Data fragmentation across multiple websites and APIs
- Strict API rate limits requiring careful request management
- Limited historical data availability in APIs
- Critical information locked in PDF documents
- Inconsistent and sometimes outdated data, especially for current Congress
Solution
To address these challenges, I needed to have a robust data collection system.
I needed the system to:
- Excel at JSON data processing
- Support flexible integration of multiple data sources and APIs
- Implement a clear, extensible class structure for future growth
- Cache progress during operations such as API crawls
- Manage rate limits with sophisticated exponential backoff
- Extract structured data from PDFs
- Process media files using tools like FFMPEG
- Provide a powerful CLI for granular task control
- Report collection progress to a central database
- Run efficiently on affordable hardware like Raspberry Pis
I chose TypeScript for implementation, leveraging Node.js's excellent single-threaded performance and native JSON handling capabilities. This aligned perfectly with the JSON-based APIs common in congressional data sources.
While I initially explored building upon the open-source Congress project, I ultimately decided to create a new solution. The existing Python-based system couldn't meet my requirements for performance and scalability, particularly when running on resource-constrained hardware.
System Design
I designed the system with a user-first approach, starting with the command-line interface (CLI). This strategy ensured the data collector would be both intuitive and extensible, with a clean class structure that supports easy expansion of features and data sources.
The CLI interface was designed with user experience in mind, offering fine-grained control over:
- Data Selection: Choose specific datasets (e.g., member biographies, photos)
- Processing Steps: Control which data processing phases would run. (e.g. only collect and validate data)
Data Processing Pipeline
The data processing pipeline consists of distinct phases:
- Collection: Gathering raw data from sources
- Validation: Verifying data structure and content
- Refinement: Parsing PDFs, correcting errors, merging sources
- Secondary Validation: Ensuring refined data integrity
- Storage: Distributing to various backends (database, S3, YouTube)
- Progress Persistence: Enable checkpoint-based recovery
- Congress Selection: Target specific congressional sessions
- Reporting: Configure email notifications for task completion/failure
Data Sources
The system pulls data from authoritative sources including, but not limited to:
- Official Government APIs (Congress.gov, GovInfo, OpenFEC)
- Legislative Websites (Senate.gov, House.gov)
- Public Information Portals (Wikipedia, C-SPAN)
- Government Data Repositories (US Census, United States GitHub)
Infrastructure
The collection processes run automatically via multiple CRON jobs on a Kubernetes cluster powered by a Raspberry Pi 5, ensuring reliable, up-to-date information while maintaining cost efficiency.
Automated Data Collection Monitoring
To ensure the data collection process is running smoothly, I've implemented a monitoring system that sends me an email if any of the CRON jobs fail.
Failed Data Collection Email Report
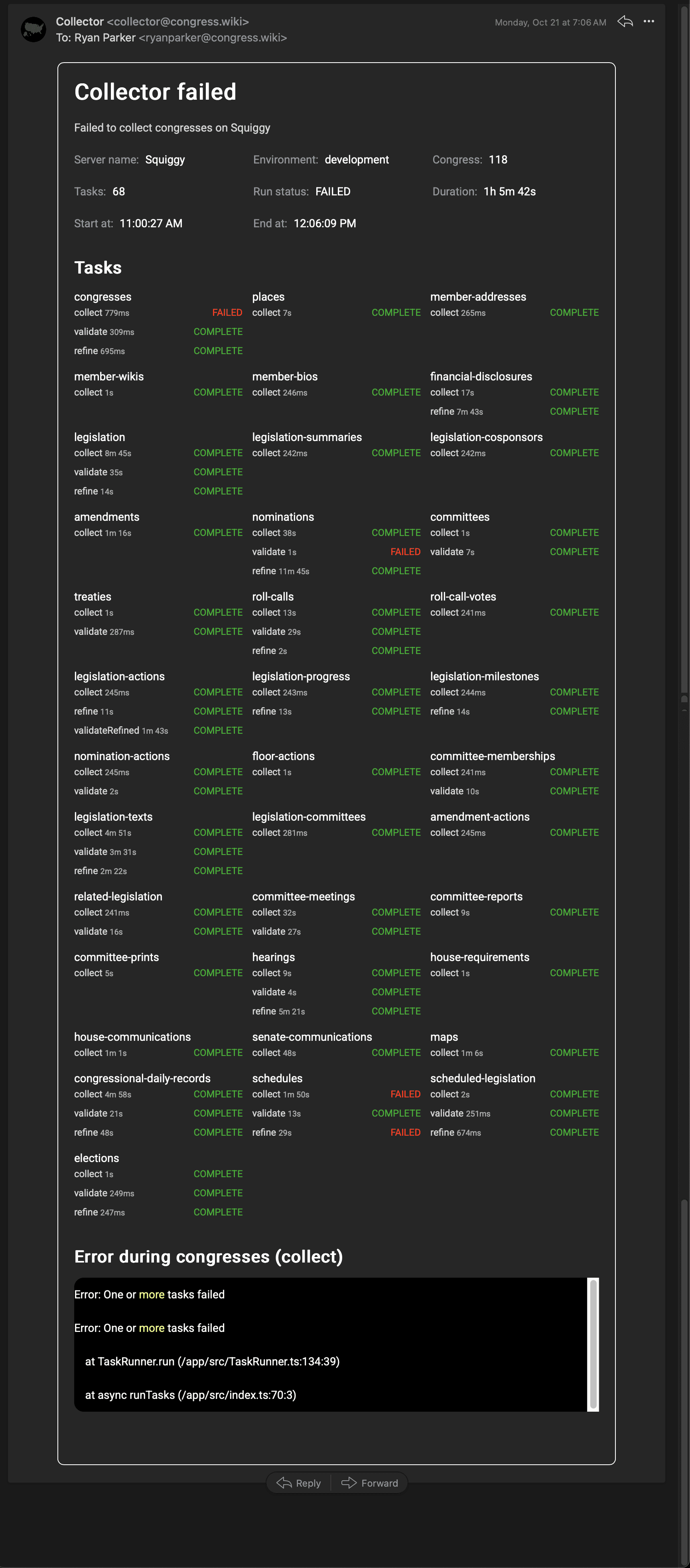
A snapshot of the automated email alert system, demonstrating the robust monitoring of the data collection processes.
Maps of the United States
One of the key principles of Congress.wiki was to present congressional data in a "Geographic Context". Congressional data is inherently geographic, and presenting it in a geographic context makes it more tangible and accessible. To accomplish this I knew I needed to have a map of not only the United States, but also its congressional districts.
Building the Maps
While getting an SVG of the United States map is rather easy and there are many freely available options on the internet, getting the same for congressional districts is not. I found a few sources that offered to sell the congressional district maps, however the cost was unreasonably high and updates were not included. Congressional districts change over time, so I needed a way to make sure my map was always up to date. I eventually came to terms that I not needed to build my own map.
To start I needed to find a source of congressional district data. I eventually found the United States Census Bureau's TIGER/Line Shapefile. These shapefiles contain detailed geographic data for the United States, including congressional districts. By using the Census's API I was able to extend my collection system to automatically gather the shapefiles and process them into usable formats such as SVGs. I accomplished this using:
- GeoJSON (a JSON format used to represent geographic data)
- topoJSON (an extension of GeoJSON used to stitch together multiple GeoJSON files).
To build the map I broke the process down into the following steps:
- Gather shapefiles for each congressional district
- Convert the shapefiles into GeoJSON
- Combine the GeoJSON into topoJSON files
- Convert the topoJSON into SVGs
The Interactive Map
I believe interactivity is a great way to improve user engagement. Having played many video games throughout my life, I had a lot of experience with interactive maps and i've come to appreciate the careful design choices that go into them. So I decided to take some of my favorite features from video game maps and build an interactive congressional district map.
Exploring the Congressional District map
Explore congressional districts through a dynamic, SVG-based map powered by D3 and U.S. Census data.
To build the interactive map, I utilized the topoJSON produced by my collector program. I fed the topoJSON data into D3 and drew the SVG. D3's extensive API allowed me to easily add interactivity such as zooming, dynamically changing fill colors, and modifying shape rendering algorithms based on the current map zoom level.
I noticed that some lower-end devices would sometimes struggle to render the map transitions and would often stutter or snap to the final state.
To optimize the map for performance, I used D3's attribute APIs to optimize the SVG rendering algorithm depending on the current zoom level.
I accomplished this by using the shape-rendering css attribute. This attribute provides hints to the renderer about what tradeoffs to make when rendering shapes. I decided to switch betwen the following configurations:
-
optimizeSpeed: This value directs the user agent to emphasize rendering speed over geometric precision or edge crispness. The final rendering is likely to skip techniques such as anti-aliasing. -
auto: This value directs the user agents to make tradeoffs in order to balance speed, edge crispness, and geometric precision, with geometric precision given more importance than speed and edge crispness.
When zoomed out, the map renders all states and congressional districts with shape-rendering: optimizeSpeed. This improved rendering performance especially on lower-end devices without introducing noticable visual regressions.
When zoomed in, all non-focused congressional districts are hidden. The focused state and congressional district borders are rendered with shape-rendering: auto to ensure accurate borders. All non-focused state borders render with shape-rendering: optimizeSpeed.
This approach resolved 90% of the performance issues I was experiencing without introducing noticable regressions.
AI-Generated Summaries
AI-Generated Bullet Point Summary for HR 1540
Watch as my AI system generates a concise, easy-to-understand summary of complex legislation in real-time.
To make legislative language more accessible, I've implemented an AI-powered summary generator that creates concise, easy-to-understand explanations of complex text such as legislation. The system works through an optimized pipeline:
- First checks for existing summaries in the database for instant retrieval
- For new summaries, sends the bill text to OpenAI's API with custom prompting to ensure consistent, high-quality output
- Streams the AI response directly to the database.
- During this time, the client will open a websocket connection to the database to stream the summary to the user interface in real-time.
- Once finished the page is revalidated and cached.
This architecture provides several benefits:
- Instant access to existing summaries
- Real-time streaming feedback as summaries are generated
- Efficient resource usage by avoiding duplicate API calls
- Consistent summary quality through careful prompt engineering
- Scalable design that can handle high concurrent usage
Postcard Advocacy Service
Congress.wiki Postcard Service Demo
A walkthrough of my postcard service, showcasing the process from message composition to recipient selection and checkout.
The postcard service allows users to directly engage with their representatives:
- Users compose messages and select recipients.
- AI moderation ensures appropriate content.
- Seamless integration with Stripe for secure payments.
- Automated postcard ordering and delivery tracking.
Unique features:
- Constituent identification through postcard design. If the postcard is from a constituent, the postcard design will be red, otherwise it will be white.
- Response rate tracking via centralized return addressing.
Through user research and feedback from political staffers, I've refined my approach to ensure maximum impact and compliance with official communication protocols.
Infrastructure
The majority of Congress.wiki's infrastructure is written in CDK (Cloud Development Kit, TypeScript) and deployed to AWS. The actual Next.js site is hosted on Vercel. Requests to specific routes are routed from Vercel to either the Next.js site or AWS infrastructure.
AWS infrastructure includes:
- RDS Postgres database
- Hasura GraphQL server on a auto scaling ECS cluster.
- S3 for cheap static file storage (images, videos, etc.).
- A step function orchestration to handle generating AI text and storing it in the database.
I chose Vercel to host the Next.js site for a few key reasons:
-
Seamless Next.js Integration: As the creators of Next.js, Vercel provides immediate access to new Next.js features and optimizations. One less thing for me to maintain.
-
Developer Experience: The platform offers zero-config deployments and excellent monitoring tools, saving significant development time.
I explored several alternatives:
- Direct AWS Deployment: While possible, it would require custom configuration for edge functions and other Next.js features.
- serverless-next.js: Lacks support for Next.js 13's app directory, which I need for SSR.
- cdk-nextjs: Aligns with my CDK infrastructure but requires more maintenance and lacks feature parity with Vercel.
Currently, Vercel's $20/month cost is reasonable for the value it provides. However, I'll likely reconsider using cdk-nextjs as a potential alternative if costs increase significantly.
My initial architecture routed traffic from AWS CloudFront to Vercel, but this approach presented several challenges:
-
CDN Complexity: Vercels infrastructure already includes a CDN. Stacking two CDNs (Vercel and CloudFront) created cache invalidation conflicts and added unnecessary complexity to the infrastructure.
-
Security Issues: SSL origin errors occurred during authentication checks and Content Security Policy (CSP) header injection in the middleware layer.
-
Limited Platform Benefits: CloudFront's presence as an intermediary prevented full utilization of Vercel's built-in analytics and security features, including their sophisticated threat detection system.
For a detailed technical explanation, I recommend reading Vercel's comprehensive guide: Reasons not to use a proxy on top of Vercel.
The current architecture is more streamlined:
- The Congress.wiki domain is managed through AWS Route 53
- An A record directs traffic directly to Vercel's infrastructure
- A custom Vercel configuration routes specific paths to AWS services via a dedicated subdomain (e.g.,
app.congress.wiki)
This setup maximizes the benefits of both platforms - leveraging Vercel's global CDN and edge functions, while maintaining direct access to AWS services where needed.
What's Next?
Congress.wiki has made significant strides in making congressional information more accessible, but there's still much to be done. While I'm currently focusing on other projects, I remain committed to maintaining and enhancing the platform. Key areas for future development include:
- Expanding educational resources for students and teachers
- Improving real-time updates for congressional activities
- Enhancing mobile experience and accessibility features
- Adding more interactive data visualizations
- Adding more AI tools to help users understand congressional information
- Adding more congressional data and historical context
You can track progress and upcoming features on our Project Roadmap on GitHub. I welcome community feedback to help shape the future of Congress.wiki.
You can support Congress.wiki by sharing the website with others and providing feedback on the website (via the Feedback button at the bottom of every page). Thank you to everyone who has supported the project so far!